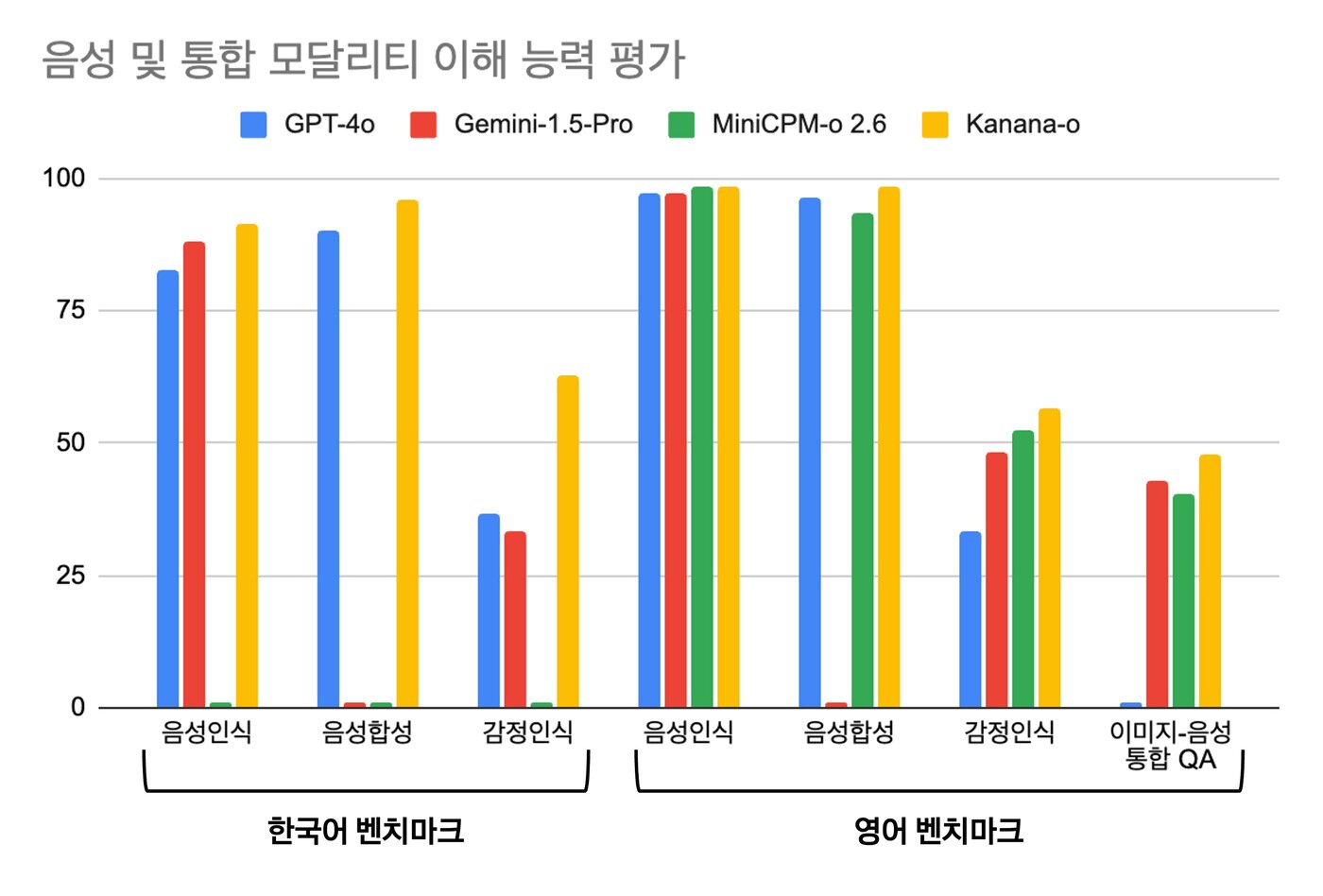
카나나-o 창작 예시카나나-o 성능관련 키워드카카오손엄지 기자 코스닥, 구조개편 칼 뽑았다…"2029년엔 상장사 10%가 퇴출 대상"한국회계기준원, 제10대 원장에 곽병진 카이스트 교수 선임관련 기사카카오 판교에 또 폭발물 설치 협박…이번엔 이재명 대통령 사칭'오리온 3세' 담서원 부사장 됐다…그룹 미래사업 총괄 중책카카오뱅크, 주담대 중도상환해약금 면제 6개월 연장첨단 GPU 4000여장 지원…산·학·연 과제 공모 개시어선원 안전보건, '운'의 영역에서 '과학'의 영역으로[기고]