"음성 속 감정 읽고 표정 바꾼다"…UNIST AI 모듈 개발
- 김세은 기자
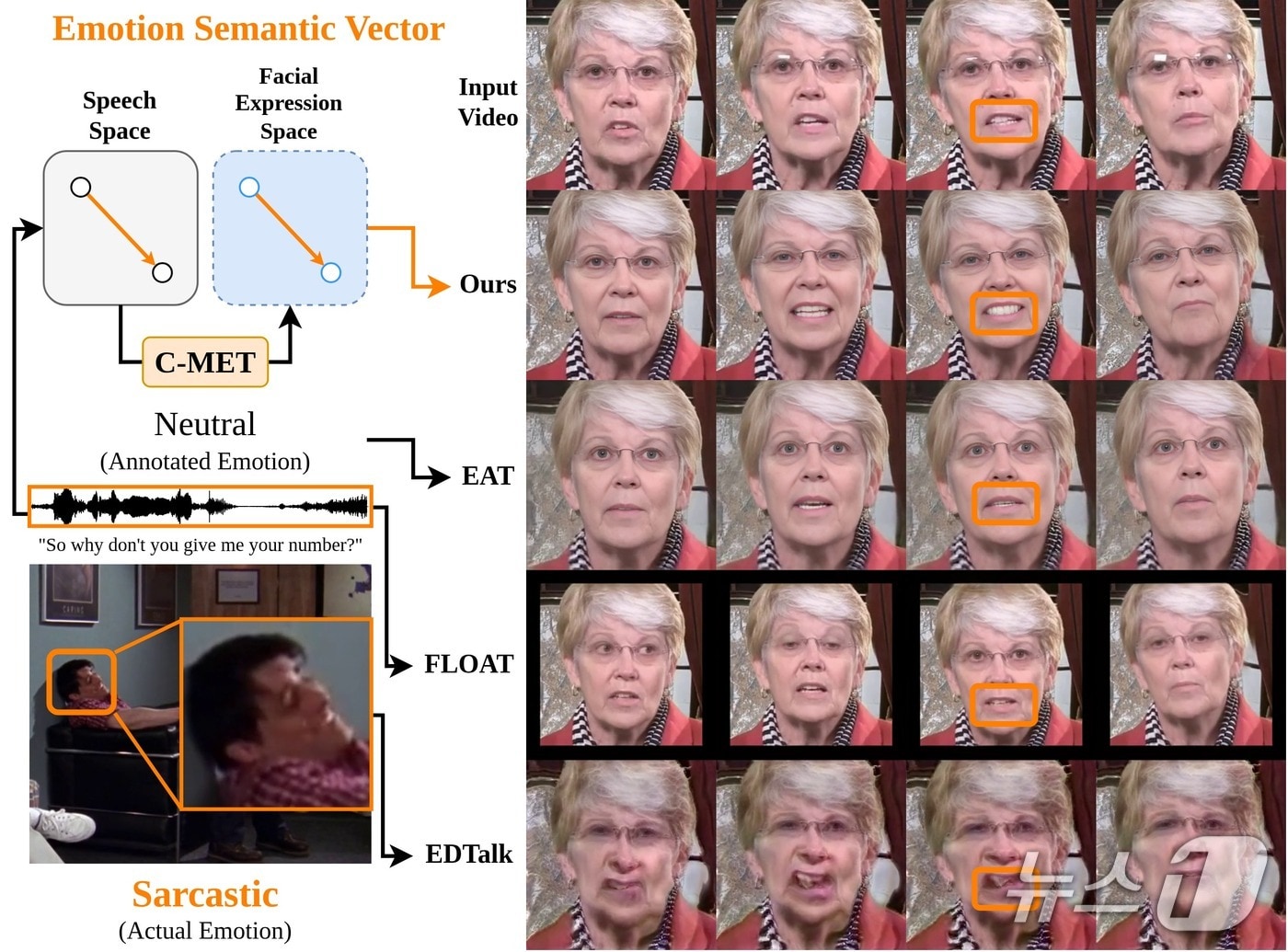
(울산=뉴스1) 김세은 기자 = 사람의 음성에서 미묘한 감정을 인식해 영상 속 화자의 표정을 바꿀 수 있는 인공지능 기술이 개발됐다.
울산과학기술원(UNIST) 인공지능대학원 김태환 교수팀은 음성 신호에서 감정을 추출해 영상 속 화자의 표정을 원하는 감정으로 바꿀 수 있는 AI 모듈인 C-MET(Cross-Modal Emotion Transfer)을 개발했다고 18일 밝혔다.
C-MET은 음성에 담긴 감정의 '변화량'을 표정의 '변화량'으로 옮기는 것이 특징이다.
중립적 음성과 감정이 실린 음성의 차이를 벡터, 즉 변화의 방향과 크기를 담은 숫자 정보로 계산한다. 벡터가 얼굴에서 어떤 표정 변화로 나타나는지를 AI가 학습한다.
음성 안에 말의 내용과 감정이 함께 섞여 있어도, 표정 변화에 필요한 감정 신호를 따로 읽어낼 수 있다. 같은 문장이라도 어조가 달라지면 입꼬리, 눈썹, 눈 주변 움직임이 다르게 나타나는 원리다.
AI가 감정을 정해진 범주로 분류하는 데 그치지 않고 연속적인 변화로 이해하도록 설계된 것이다.
또 각각의 감정에 슬픔, 기쁨 같은 이름표를 붙여 학습시키는 기존의 방식과 달리, 두 감정 사이의 변화량을 본다.
이 덕분에 비꼼, 공감, 카리스마처럼 학습하지 않은 미묘한 감정도 표정에 반영할 수 있다. 감정이 담긴 음성을 입력으로 쓰기 때문에 감정을 표현한 참조 이미지도 필요 없다.
이 기술은 최신 말하는 표정 편집 기술인 '이디톡(EDTalk)'과 비교해 감정 표현 정확도가 14%포인트(p) 이상 높았다. 또 다른 말하는 얼굴 생성 모델인 'PD-FGC'에도 C-MET을 적용한 결과 감정 정확도가 3.36%p로 높아졌다.
김태환 교수는 "이번 연구는 이미지 없이 음성만으로 얼굴 영상의 감정을 바꿀 수 있다는 점에서 기존 방식들의 한계를 해결했다"며 "가상 인간 제작, 영화·콘텐츠 후반 작업, 감정 인식 AI 등에 폭넓게 활용될 수 있는 기술"이라고 설명했다.
이번 연구 최찬혁 UNIST 인공지능대학원 석사과정생이 제1저자로 참여했다. 성과는 인공지능 및 컴퓨터 비전 분야 최우수 국제학회 CVPR(Computer Vision and Pattern Recognition) 2026에 채택됐다. 연구팀의 프로젝트 페이지에서 코드·체크포인트·데모 영상을 확인할 수 있다.
syk000120@news1.kr
Copyright ⓒ 뉴스1. All rights reserved. 무단 전재 및 재배포, AI학습 이용금지.









