데이터드리븐, Edu-BERT 활용 '문장생성' 모델 개발
- 임해중 기자
(서울=뉴스1) 임해중 기자 = 데이터드리븐은 교육분야 자연어처리 모델인 Edu-BERT와 GPT2를 활용한 인공지능 문장생성 모델을 새롭게 개발했다.
Edu-BERT는 지난 2018년 11월 구글이 발표한 언어모델인 BERT(Bidirectional Encoder Representations from Transformers)에서 교육 도메인 특성을 반영하여 재학습한 언어재현표현 모델로, 데이터드리븐에 따르면 기존 한국어 BERT 모델은 모델을 구성하는데 사용한 단어의 특성이 다르기에 교육분야 활용을 위해서는 추가 데이터를 수집하고 학습을 진행해야 했으나, 이번 Edu-BERT의 개발을 통해 이러한 제약을 극복하게 됐다.
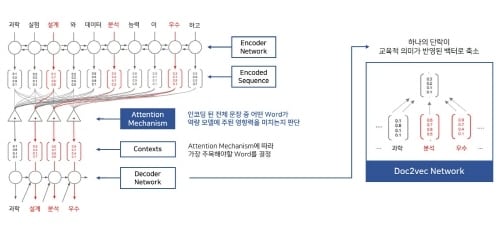
데이터드리븐은 이 Edu-BERT를 구성하기 위해 2019년부터 2021년까지 교육분야 사업을 진행하며 수집한 ‘교육 활동 기록 데이터’를 형태소 단위로 분리하고, Attention & Doc2Vec Network를 통해 교육적인 의미가 강한 단어의 가중치를 조정하는 과정을 거친 것으로 알려졌다. 구성된 Edu-BERT 모델을 활용하여 약 14만 건의 교육 활동기록 데이터의 임베딩을 수행하여 한국지능정보사회진흥원이 주관한 2021년 인공지능 학습용 데이터 구축 사업의 ‘텍스트 기반 학생 청소년 핵심역량분석 모델’의 개발에 기여하기도 했다.
Edu-BERT가 교육 도메인 특성을 반영한 언어재현표현 모델이라면, 문장생성 모델은 Edu-BERT와 GPT2을 결합시켜 개발한 교육 분야 인공지능 모델이라는 점도 특징이다. 인공지능 문장생성 모델은 교수자가 학습자를 관찰하는 다양한 기준의 지표에서 상세한 서술을 생성하는 기능을 수행하며, 교수자의 관점과 판단의 방향성을 유지한 채로 문장을 생성, 교수자의 수업 기록 업무에 대한 부담을 경감할 수 있다. 데이터드리븐은 Edu-BERT 모델과 문장생성 모델을 활용한 ‘AI 기반 청소년역량진단 온라인 관리 플랫폼’ 서비스를 성남시청소년재단 산하기관에 구축 완료하고 사용을 준비하고 있다.
김기범 데이터드리븐 부사장은"Edu-BERT와 인공지능 문장생성 모델을 활용한 서비스의 확장을 통해, 더 많은 데이터를 수집하고 인공지능 성능을 고도화 할 수 있는 선순환 구조를 구축 중"이라며 "올해 중 대규모 교육 데이터 추가 수집을 진행해 더 많은 영역에 적용할 수 있는 인공지능 모델과 서비스를 개발할 것이다"고 말했다.
haezung2212@news1.kr
Copyright ⓒ 뉴스1. All rights reserved. 무단 전재 및 재배포, AI학습 이용금지.