 |
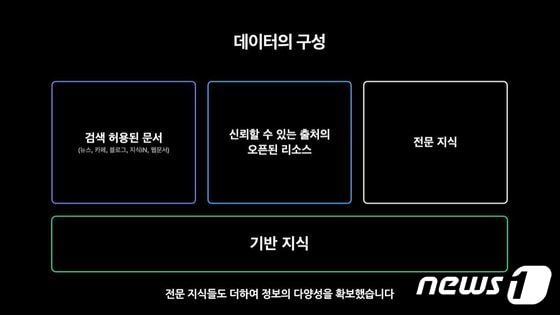
| 네이버 초대규모 AI '하이퍼클로바'의 데이터 구성. (네이버 제공)© 뉴스1 |
네이버의 초대규모 인공지능(AI) '하이퍼클로바'의 핵심은 초대규모 데이터와 서버, 인력이다.
특히 국내 포털 1위 사업자로서 인터넷 '관문'을 지키며 막대한 한국어 데이터를 보유하고 있다는 점은 최대 경쟁력으로 꼽힌다. 일론 머스크 테슬라 최고경영자(CEO)가 설립한 비영리 AI 연구회사 '오픈AI'가 개발하고 현존하는 최고 AI로 평가받는 'GPT-3'는 영어 기반. 하이퍼클로바는 GPT-3보다 한국어 데이터를 6500배 이상 학습했다.
하이퍼클로바가 학습하는 한국어 데이터는 먼저 범용성과 완결성을 고려해 객관적 사실 중심의 '기반 지식'을 바탕으로 했다.
여기에 검색이 허용된 범위에서 네이버 뉴스·블로그·지식인·카페·웹문서를 품질 순으로 줄을 세운 뒤 차례대로 가져왔다.또 국립국어원의 빅데이터 모음집 '모두의 말뭉치'처럼 신뢰할 수 있는 출처의 오픈된 소스를 '고품질 출처'로 간주해 추가했고, '전문지식'을 더해 정보의 다양성을 확보했다.
강인호 책임리더는 지난 26일 '네이버 AI 나우' 콘퍼런스에서 "품질 순서로 문서를 가져올 때 이왕이면 동일한 개수의 문서라도 다양한 내용을 담기 위해 문서 내용이 유사한 경우 중복 제거를 진행했다"며 "이는 한쪽 내용으로 치우치지 않기 위해서기도 하다"고 말했다.
네이버는 하이퍼클로바 개발 과정에서 대용량 데이터를 준비하면서 △다양한 내용 △범용의 구성 △양질의 정보 △충분한 크기 4가지를 고려했다.
강 책임리더는 "우리가 일상에서 접할 수 있는 다양한 정보와 모습이면서 저희가 목표로 하는 검색, 대화, Q&A, 요약 등 여러 생성작업을 포함해야 한다"며 "그 내용은 믿고 신뢰할 수 있는 양질의 것이고, 목표로 하는 언어모델의 크기를 구축하는 데 충분한 양을 구축하고자 했다"고 말했다.
이어 "품질 좋은 특정 유형을 하나씩 확보해나간다기보다는 한국에 있는 전반적 데이터를 가져다 놓고 품질 좋은 순서대로 가져왔다"고 했다.
 |
| 강인호 책임리더가 지난 26일 '네이버 AI 나우'에서 국내 최초 초대규모 AI '하이퍼클로바'를 개발하기 위한 데이터 수집에서 고려 요소를 설명하고 있다. (네이버 제공)© 뉴스1 |
하이퍼클로바는 이같이 선별하고 정제한 데이터로부터 최종적으로 1.96테라바이트(TB) 상당의 데이터셋을 구축했다.
이는 5600억개 토큰 데이터 셋으로, 한국어 위키피디아의 2900배, 뉴스 50년치, 네이버 블로그 9년치에 해당한다.
하이퍼클로바 학습 데이터의 개인정보 보호는 제대로 이뤄졌을까.
강 책임리더는 "개인정보 수집을 지양하고 있으나 사용자들이 전체공개로 지정해 수집되는 정보들, '검색 허용'한 문서들에 대해서 혹시나 포함될 수 있는 개인정보는 제거하거나 비식별화를 진행했다"고 말했다.
개인정보 이슈는 이제 막 열리기 시작하는 AI 개발 시장에서 최대 화두다.
앞서 AI 챗봇 '이루다' 개발사 스캐터랩은 2020년 2월부터 2021년 1월까지 자사 앱 서비스인 '텍스트앳'과 '연애의 과학'에서 수집한 이용자 약 60만명의 카카오톡 대화문장 94억여건을 이루다 개발에 이용하는 과정에서 카카오톡 대화에 포함된 이름과 휴대전화번호, 주소 등 개인정보를 삭제하거나 암호화 조치를 전혀 하지 않은 것으로 확인돼 지난달 개인정보보호위원회로부터 1억330만원의 과징금·과태료를 부과 받았다.
이에 "스타트업 죽이기"란 반발과 함께 개인정보위의 결정이 AI 서비스 개발을 위한 개인정보 수집·이용 기준을 제시했다는 점에서 '불확실성'을 해소했다는 평가가 나왔다.
개인정보위가 개인정보보호법 개정안에 따라 신설된 '가명정보 처리 특례'상 '과학적 연구'에 '산업적 연구'를 포함해 사업자의 서비스 개발을 위한 가명정보 처리를 허용한다고 해석했다는 점도 주목할 만하다.
가명정보는 개인정보의 일부를 삭제하거나 일부 또는 전부를 대체하는 방법으로 추가 정보 없이는 특정 개인을 알아볼 수 없도록 처리한 정보로, 개정된 개인정보보호법은 개인정보 처리자가 통계 작성이나 과학적 연구, 공익적 기록 보존을 위해서라면 정보주체의 동의 없이 처리할 수 있도록 허용했다.
son@news1.kr












![장기용·천우희, 사과 물고 간접키스...아찔 케미 [N화보]](https://image.news1.kr/system/photos/2024/4/24/6614728/no_water.jpg/dims/resize/276/crop/276x184/thumbnail/138x92!/optimize)